What the SQL?!? WINDOW¶

Today's "What the SQL?!?" features the keyword WINDOW. This clause allows
us to elegantly select results from the previous results from the previous results
from the previous results...
Please note, our target database is PostgreSQL. These examples may work with
other databases, but might need some massaging to get them to work properly.
Search online for the specific vendor's documentation if errors pop up.
Try searching for "WINDOW queries $DB_VENDOR_NAME". Not all database vendors
support the keyword WINDOW.
Create Sample Data¶
DROP TABLE IF EXISTS sample_moves;
CREATE TABLE sample_moves AS
SELECT
column1::int AS id,
column2::varchar AS name,
column3::varchar AS address,
column4::date AS moved_at
FROM (
VALUES
(1, 'Alice' , '1 Main St', '2017-01-01'),
(2, 'Bob' , '2 Main St', '2017-02-01'),
(3, 'Cat' , '2 Main St', '2017-03-01'),
(4, 'Dan Sr' , '3 Main St', '1970-04-01'),
(5, 'Dan Jr' , '3 Main St', '2001-04-01'),
(6, 'Dan 3rd' , '3 Main St', '2017-04-01')
) as t
;
CREATE INDEX ON sample_moves(address);
SELECT * FROM sample_moves;
Results:¶
| id | name | address | moved_at |
|---|---|---|---|
| 1 | Alice | 1 Main St | 2017-01-01 |
| 2 | Bob | 2 Main St | 2017-02-01 |
| 3 | Cat | 2 Main St | 2017-03-01 |
| 4 | Dan Sr | 3 Main St | 1970-04-01 |
| 5 | Dan Jr | 3 Main St | 2001-04-01 |
| 6 | Dan 3rd | 3 Main St | 2017-04-01 |
Life Without Windows¶
A quick poem...
Eyes big and wide,
nothing seen inside.
Feeling around
nothing abound.
This things wet,
toxic I bet.
Closing my eyes,
still can't rest.
Having a window,
would be best.
How many people live at each address?¶
Using a standard GROUP BY with COUNT we consolidate the records and count
how many rows belong to each address.
Tip:
COUNT(1)is more efficient thanCOUNT(*).
SELECT
address,
COUNT(1) total
FROM sample_moves
GROUP BY address
ORDER BY address;
Results:¶
| address | total |
|---|---|
| 1 Main St | 1 |
| 2 Main St | 2 |
| 3 Main St | 3 |
How many people live with each person?¶
Enter subquery land. Life without windows is not exciting.
SELECT
*,
(
SELECT
-- everyone at the address, minus the person
COUNT(1) - 1
FROM sample_moves t2
WHERE t2.address = t1.address
) AS others
FROM sample_moves t1;
Results:¶
| id | name | address | moved_at | others |
|---|---|---|---|---|
| 1 | Alice | 1 Main St | 2017-01-01 | 0 |
| 2 | Bob | 2 Main St | 2017-02-01 | 1 |
| 3 | Cat | 2 Main St | 2017-03-01 | 1 |
| 4 | Dan Sr | 3 Main St | 1970-04-01 | 2 |
| 5 | Dan Jr | 3 Main St | 2001-04-01 | 2 |
| 6 | Dan 3rd | 3 Main St | 2017-04-01 | 2 |
JOIN works, too¶
SELECT
t1.*,
t2.others
FROM sample_moves t1
JOIN (
SELECT
address,
COUNT(1) - 1 as others
FROM sample_moves
GROUP BY address
ORDER BY address
) t2 USING (address);
And so does JOIN LATERAL¶
SELECT
t1.*,
t2.others
FROM sample_moves t1
JOIN LATERAL (
SELECT
address,
COUNT(1) - 1 as others
FROM sample_moves sub
WHERE sub.address = t1.address
GROUP BY address
ORDER BY address
) t2 ON true;
That's nice, but who moved in first?¶
SELECT
*,
(
SELECT
COUNT(1) - 1
FROM sample_moves t2
WHERE t2.address = t1.address
) AS others,
(
SELECT
name
FROM sample_moves t3
WHERE t3.address = t1.address
ORDER BY moved_at ASC
LIMIT 1
) AS first_person
FROM sample_moves t1;
Wait I thought this was about windows?!?¶
The keyword OVER is the gateway drug into WINDOW functions. Using OVER
with parenthesis is an inline window. The PARTITION BY keywords gives similar
functionality to GROUP BY and JOIN ... USING all in one power packed
statement. It can never reduce the number of records in a result set which is
the same behavior expected of a correlated subquery.
PARTITION BY is treated the same as the traditional GROUP BY. The ORDER BY
also has the same behavior as its use in a standard query.
SELECT
*,
(count(1) OVER (PARTITION BY address)) - 1 AS others,
first_value(name) OVER (PARTITION BY address ORDER BY moved_at) AS first_moved
FROM sample_moves;
Results¶
| id | name | address | moved_at | others | first_moved |
|---|---|---|---|---|---|
| 1 | Alice | 1 Main St | 2017-01-01 | 0 | Alice |
| 2 | Bob | 2 Main St | 2017-02-01 | 1 | Bob |
| 3 | Cat | 2 Main St | 2017-03-01 | 1 | Bob |
| 4 | Dan Sr | 3 Main St | 1970-04-01 | 2 | Dan Sr |
| 5 | Dan Jr | 3 Main St | 2001-04-01 | 2 | Dan Sr |
| 6 | Dan 3rd | 3 Main St | 2017-04-01 | 2 | Dan Sr |
A picture with arrows worth a thousand words:
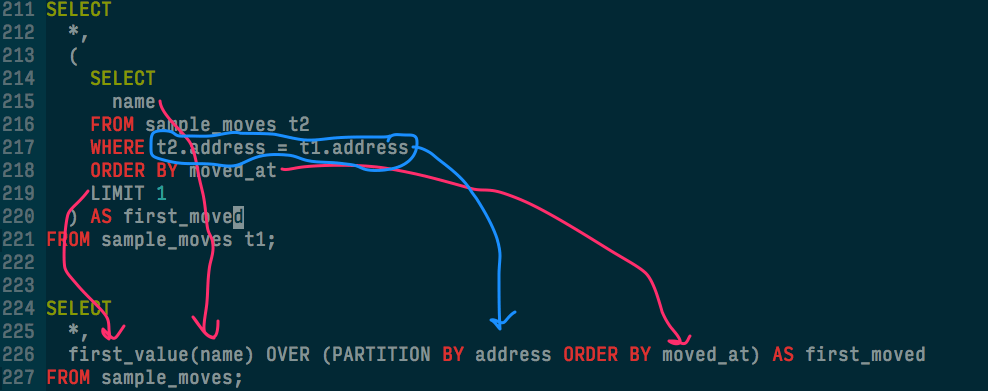
That doesn't look very DRY. Finally, a WINDOW¶
The WINDOW keyword allows us to alias the options of the OVER clause. Namely
the expression (...) between and including the parenthesis.
In the following example we add the use of RANGE to provide additional
direction to the windowing clause.
SELECT
*,
(count(1) OVER w) - 1 AS others,
first_value(name) OVER w AS first_moved,
last_value(name) OVER w AS last_moved
FROM sample_moves
WINDOW w AS (
PARTITION BY address ORDER BY moved_at
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
);
Results¶
| id | name | address | moved_at | others | first_moved | last_moved |
|---|---|---|---|---|---|---|
| 1 | Alice | 1 Main St | 2017-01-01 | 0 | Alice | Alice |
| 2 | Bob | 2 Main St | 2017-02-01 | 0 | Bob | Bob |
| 3 | Cat | 2 Main St | 2017-03-01 | 1 | Bob | Cat |
| 4 | Dan Sr | 3 Main St | 1970-04-01 | 0 | Dan Sr | Dan Sr |
| 5 | Dan Jr | 3 Main St | 2001-04-01 | 1 | Dan Sr | Dan Jr |
| 6 | Dan 3rd | 3 Main St | 2017-04-01 | 2 | Dan Sr | Dan 3rd |
-- Previous and Next Record
SELECT
*,
(count(1) OVER w) - 1 AS others,
first_value(name) OVER w AS first_moved,
last_value(name) OVER w AS last_moved,
lag(id) OVER (ORDER BY id) AS prev_id,
lead(id) OVER (ORDER BY id) AS next_id
FROM sample_moves
WINDOW w AS (
PARTITION BY address
ORDER BY moved_at
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
)
ORDER BY address;
Results¶
| id | name | address | moved_at | others | first_moved | last_moved | prev_id | next_id |
|---|---|---|---|---|---|---|---|---|
| 1 | Alice | 1 Main St | 2017-01-01 | 0 | Alice | Alice | 2 | |
| 2 | Bob | 2 Main St | 2017-02-01 | 1 | Bob | Cat | 1 | 3 |
| 3 | Cat | 2 Main St | 2017-03-01 | 1 | Bob | Cat | 2 | 4 |
| 4 | Dan Sr | 3 Main St | 1970-04-01 | 2 | Dan Sr | Dan 3rd | 3 | 5 |
| 5 | Dan Jr | 3 Main St | 2001-04-01 | 2 | Dan Sr | Dan 3rd | 4 | 6 |
| 6 | Dan 3rd | 3 Main St | 2017-04-01 | 2 | Dan Sr | Dan 3rd | 5 |
List Window Functions¶
Here is a list from Postgres docs of all the window functions. In addition to these, any regular aggregate function can be use within a window.
| Function | Description |
|---|---|
| row_number() | number of the current row within its partition, counting from 1 |
| rank() | rank of the current row with gaps; same as row_number of its first peer |
| dense_rank() | rank of the current row without gaps; this function counts peer groups |
| percent_rank() | relative rank of the current row: (rank - 1) / (total rows - 1) |
| cume_dist() | relative rank of the current row: (number of rows preceding or peer with current row) / (total rows) |
| ntile | integer ranging from 1 to the argument value, dividing the partition as equally as possible |
| lag() | returns value evaluated at the row that is offset rows before the current row within the partition; if there is no such row, instead return default (which must be of the same type as value). Both offset and default are evaluated with respect to the current row. If omitted, offset defaults to 1 and default to null |
| lead() | returns value evaluated at the row that is offset rows after the current row within the partition; if there is no such row, instead return default (which must be of the same type as value). Both offset and default are evaluated with respect to the current row. If omitted, offset defaults to 1 and default to null |
| first_value() | returns value evaluated at the row that is the first row of the window frame |
| last_value() | returns value evaluated at the row that is the last row of the window frame |
| nth_value() | returns value evaluated at the row that is the nth row of the window frame (counting from 1); null if no such row |
References¶
- Postgres Window Tutorial: https://www.postgresql.org/docs/9.3/static/tutorial-window.html
- Postgres Window Functions: https://www.postgresql.org/docs/9.3/static/functions-window.html
- Postgres Window Syntax: https://www.postgresql.org/docs/9.3/static/sql-expressions.html#SYNTAX-WINDOW-FUNCTIONS